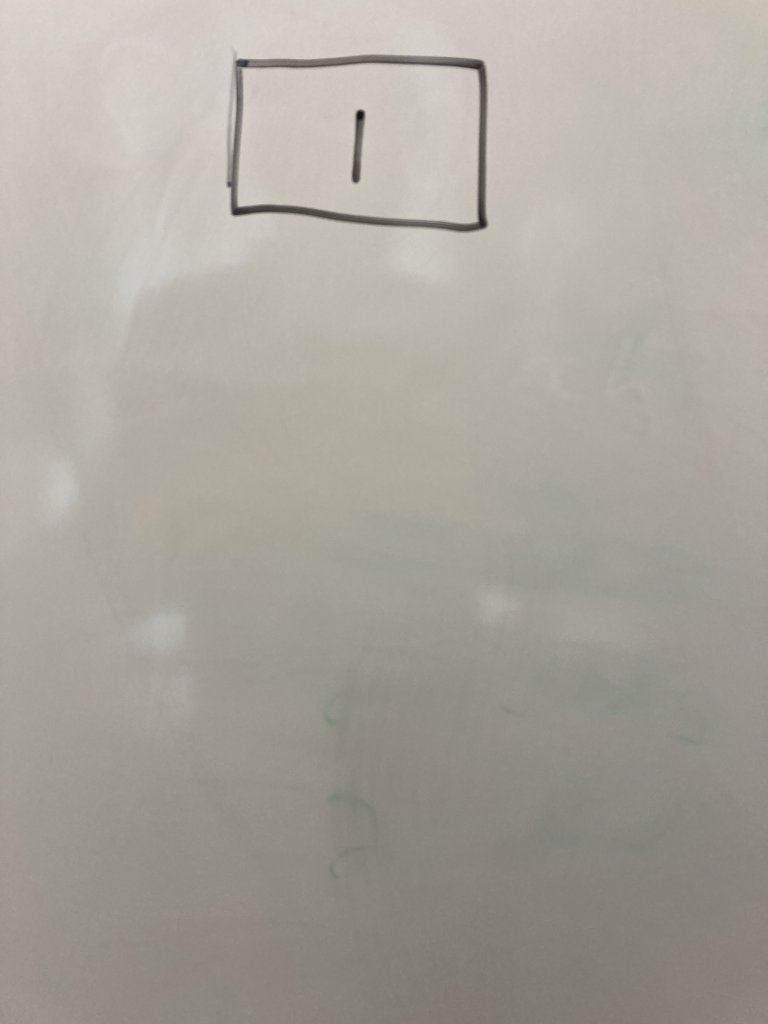Testing is integral to all forms of engineering. Software developers often write as much test code as they do product code! This set of labs introduces testing concepts and automated testing.
1 - Assertions
The building block of testing.
Class video from Spring 25
Ignore the slide about exams.
Software testing
Software testing is both a manual and an automated effort.
Manual testing is when a tester (or user) enters values into the user interface and checks the behavior of the system.
Automated testing is where test code is used to check the results of the main product code. Automated testing is an essential part of program verification, which is an evaluation that software is behaving as specified and is free from errors.
Automated testing is a necessity in real systems with thousands of lines of code and many complex features. Manual testing is simply infeasible to do thoroughly.
Code that verifies code?
Automated testing in this case means writing code. Developers and testers write code and scripts that executes and tests some other code.
Exercise
Create a directory named testing-lab in your seng-201/ directory.
Download sample.py and put it in the testing-lab/ directory.
Open the folder in PyCharm and run sample.py.
The function calls in the __main__ section of code are a semi-automated test. The calls are automated, but the verification is still manual – you, the developer, have to verify that the output is indeed correct.
To have automated testing, we need a programmatic indicator of correctness. Enter the assert statement.
The assert statement
Nearly all programming languages have an assert keyword. An assertion checks if a value is True or False. If True, it does nothing. If False, the assert throws a special type of exception. Assertions are commonly used in languages like C and Ada to verify that something is True before continuing execution.
In most modern languages, including Python, the assert is the basis of automated testing.
Exercise
Let’s explore the assert in Python.
Create a new file named test_sample.py in the testing-lab/ directory. Edit the file in PyCharm.
Add the following code:
test_sample.py
assertTrueassertFalseprint("Made it to the bottom.")
Run test_sample.py. Notice the following.
assert True does not produce any output. The program simply continues.
assert Falsegenerates an exception. This is expected.
The print(...) statement did not execute because the exception generated by assert False crashed the program.
Comment out the assert False line and run it again. The print(...) statement will execute.
This demonstrates the behavior of assert. Let’s add some more interesting assertions. Add the following lines to the bottom of test_sample.py:
test_sample.py
x=2**5assertx==32asserttype("Bob")==stry=16assertx-y==16andtype("Bob")==strandint("25")==25print("Made it to the bottom.")
The right-hand side of the assert statements now use comparisons and boolean operators. This looks a bit more realistic. The assert can have any simple or complex Boolean expression so long as it evaluates to True or False.
Quick Exercise: Change the operators or values in the expressions so they evaluate to False. Notice how the last assert can fail if any of the comparisons are false.
We’ll put our assertions to work testing program code in the next lab.
Knowledge check
Question: What two things are you trying to verify with program verification?
Question: Why do we need automated testing?
Question: What happens next if a Python program encounters the statement assert True?
Question: What happens next if a Python program encounters the statement assert False?
Question: What happens when the following executes: assert 16 == 2**4?
Question: What happens when the following executes? assert len('Bob') > 0 and 'Bob' == 'Alice'
2 - Unit testing
Using assertions to test a file.
Class video
Testing sample.py
Assertions are the basis of modern automated testing. Developers write test code in source files that are separate from the main program code. We have our program code in sample.py and the test code will be in test_sample.py. This is a common naming convention.
Now, let’s use our assert to test the correctness of the functions in sample.py.
Comment out all the code in test_sample.py
Add the line import sample. In Python, this makes the content of sample.py accessible to code in test_sample.py.1
Now let’s convert those print(...) statements from sample.py into assert statements in test_sample.py. test_sample.py should now have the following:
test_sample.py
importsample# We import the filename without the .pyassertsample.palindrome_check("kayak")# the function should return True, giving "assert True"assertsample.palindrome_check("Kayak")assertsample.palindrome_check("moose")isFalse# the function should return False, giving "assert False is False", which is Trueassertsample.is_prime(1)isFalseassertsample.is_prime(2)assertsample.is_prime(8)isFalseassertsample.reverse_string("press")=="sserp"# checking result for equality with expectedassertsample.reverse_string("alice")=="ecila"assertsample.reverse_string("")==""print("All assertions passed!")
Point 1: We access the functions in sample.py by calling, e.g., sample.palindrome_check(...). The prefix sample.X tells Python “go into the sample module and call the function named X.” We would get an error if we called only sample.palindrome(...) because Python would be looking in the current running file, which has no such function defined in it.
Point 2: In Python, you should check if a value is True or False using is. The is operator returns a boolean. You could also type x == True or x == False. Either form will work, but is is preferred2.
Point 3: Remember that palindrome_check() and is_prime() return True/False themselves. We are simply verifying that they are returning the correct value. reserve_string() returns a string value, so we need to compare using == to an expected value.
Point 4: The program will crash with an AssertionError if any of the assert statements are False. Mess up one of the assertions to verify this.
Exercise
Go to sample.py and define a function named power() that takes two parameters, x and y, and returns the computed result of xʸ.
Add assert statements to test_sample.py to verify your function behaves correctly.
Unit tests
The file test_sample.py is what software engineers call an automated unit test. A unit test is a group of test code (usually one file) that verifies a single class or source file3. Unit tests are usually written by the same developer who wrote the program code.
Our automated unit test now calls functions and use assert statements to verify that they are returning the expected results. If an assertion fails, the test fails.
What does it mean if a test fails? One of two things:
Either there is something wrong in the program code. Maybe there is a logic error.
The test code itself has a mistake in its logic.
Regardless, if a test fails, you need to figure out why. A good unit test will systematically exercise all the logic of the function or module under test. This can help uncover flaws in the program code. We will discuss strategies to do this in subsequent lessons.
We also need a way to run the test code and accumulate the results in a useful way. We will do this in the next lab.
Knowledge check
Question: Suppose you wanted to test a function named get_patient_priority(str) in hospital.py. What would you have to do to call the function from your test code?
Question: The right hand side of an assert statement can be any expression (simple or complex) as long as it evaluates to _____ or _____.
Question: Who writes unit tests?
Question: The name for a test that tests an individual module is a ______ test.
Question: Why do you think we write separate assert statements for each function input, rather than one assert statement that calls the function multiple times with different inputs? That is, why not do assert sample.reverse_string("alice") == "ecila" and sample.reverse_string("") == ""?
In Python parlance, a single file is called a module. You can create complicated modules that are collections of multiple source files. This is how many popular Python libraries like random work, as do third party libraries like pytorch and keras used for machine learning. It is a way to bundle functions and classes for convenient use in source code. ↩︎
If you are dying to know the difference between x is False and x == False, it’s because many other values are equivalent to True and False when using ==. Empty values, such as 0 or [] are == False (try it). But only False is False. Similarly, only True is True, but 1 == True. ↩︎
The unit is usually a single class. However, in our case, there is no class, but a collection of functions in a file. Some people treat a file as a unit. But a file can have multiple classes in it. The definition of a unit is a bit fuzzy, but usually refers to either a class or a single file. ↩︎
3 - Structuring test code
Organizing the test code has benefits, just like organizing program code.
Limitations to the current approach
In the previous lab, we gathered our assert statements into a test file that can be run. If the test file runs to completion, our tests have passed. If it fails with an AssertionError, we know that a test has failed and something is wrong (either with the program code or the test code itself). We have the beginnings of automated unit testing.
Our current goal
What we have so far is a good start, but we have two things to improve upon:
Currently, we can only fail one assert the test file at a time because a failed assertion throws an exception and halts the program. Ideally, we would like to run all tests and identify which individual ones are failing.
We would like to collect our test results in a human-friendly format. I run the test, I get a summary of passes and fails.
We can accomplish these both these things. First, we need to organize our test cases in our test file. Second, we will need help from developer tools.
importsample# We import the filename without the .pyassertsample.palindrome_check("kayak")# the function should return True, giving "assert True"assertsample.palindrome_check("Kayak")assertsample.palindrome_check("moose")isFalse# the function should return False, giving "assert False is False", which is Trueassertsample.is_prime(1)isFalseassertsample.is_prime(2)assertsample.is_prime(8)isFalseassertsample.reverse_string("press")=="sserp"# checking result for equality with expectedassertsample.reverse_string("alice")=="ecila"assertsample.reverse_string("")==""print("All assertions passed!")
Remember, we use the naming conventiontest_<file>.py to identify the unit test for <file>.py.
Organizing test code into test cases
To meet our goal, we will first organize our assert statements into test cases, which has a conceptual and a literal definition:
test case (concept): inputs and expected results developed for a particular objective, such as to exercise a particular program path or verify that a particular requirement is met. [Adapted from ISO/IEC/IEEE 24765].
test case (literal): a test function within a test file.
Let’s start simple. Let’s move the assert statements that test each function into their own functions in the test file like so:
test_sample.py
importsample# We import the filename without the .pydeftest_palindrome():assertsample.palindrome_check("kayak")# the function should return True, giving "assert True"assertsample.palindrome_check("Kayak")assertsample.palindrome_check("moose")isFalse# the function should return False, giving "assert False is False", which is Truedeftest_is_prime():assertsample.is_prime(1)isFalseassertsample.is_prime(2)assertsample.is_prime(8)isFalsedeftest_reverse():assertsample.reverse_string("press")=="sserp"# checking result for equality with expectedassertsample.reverse_string("alice")=="ecila"assertsample.reverse_string("")==""# run the test cases when executing the fileif__name__=="__main__":test_palindrome()test_is_prime()test_reverse()
We say now that each of test_palindrome(), test_is_prime(), and test_reverse() is a test case. We have three (3) test cases in one (1) unit test file.
Note the naming convention: all the test case functions begin with the string test_. This is a requirement of the developer tool in the next lab that will help us run multiple test cases even if one of them fails.
The block beginning with if __name__ == "__main__": allows us to run the tests by running the file. You should not see any output when you run the unit test because all of these assert statements should evaluate to True.
Diversifying our test cases
One test case for each function in your program code is where you should start. However, we often want more than one test case per program code function. Why?
Consider why we have multiple simple assert statements. Suppose we have the following valid assertion: assert sample.is_prime(1) is False and sample.is_prime(2). Now, suppose this assertion failed due to a bug in our program code. The bug could either be with the logic of dealing with the input 1 or 2. We put our checks in separate assert statements so we know precisely which input caused an error in the program code.
The same strategy applies when unit testing program code.
Program paths
A program path is a sequence of instructions (lines of code) that may be performed in the execution of a computer program. [ISO/IEC/IEEE 24765] Take a look at is_prime() in sample.py:
Giving the input 1 executes lines 5, 6 and 7. This path (5,6,7) deals with special cases where our input is ≤ 1. One (1) itself is not prime, and neither are 0 or negative numbers by definition.
Giving the input 4 executes lines 5, 6, 8, 9, and 10. This path (5,6,8,9,10) accounts for numbers > 1 that are not prime.
Giving the input 5 will execute lines 5, 6, 8, 9 and 11. This path (5,6,8,9,11) accounts for numbers > 1 that are prime. The input 3 is a special case of this that does not include line 8.
Path testing
Let’s group assert statements that test “a particular program path” or “a particular requirement” (see the test case definition) into separate test cases. Change test_is_prime() to the following:
These test cases both verify is_prime() but examine different program paths.
test_is_prime_special_cases() tests path #1 (previous subsection). We know something is wrong with the part of our algorithm that handles the special case of integers ≤ 1.
test_is_prime() tests paths #2 and #3. WE know something is with the part of the algorithm that checks if the input is divisible by a potential factor if that test case fails.
The ability to pinpoint where the algorithm is failing is very useful to the developer when they go to debug. Especially when you have many test cases and hundreds of lines of program code.
Some functions only have one program path, and so one test case may be sufficient.
Your testing strategy
Writing separate test cases for each program path or requirement is a testing strategy. But, it can be hard to know how much to identify the program paths or to know how many tests are “enough”.
For now, start with one test case per program function.
Then ask yourself, “are there sets of input where the program behaves differently than for other inputs?” If so, divide your test case to separate those input sets. In is_prime(), the program behaves differently if you give it inputs ≤ 1 vs. inputs > 1 that are prime vs. inputs > 1 that are not prime.
We will discuss how to analyze a program to create a good test strategy in future lessons, as well as quantify how good our tests are.
Exercise
Our test_is_prime() has lumped together the program paths where the number is prime and the number is not. Reorganize this test into two test cases: one for each program path. Write one test case asserting only prime numbers ≥ 1, and the other only non-prime numbers ≥ 1.
Knowledge check
Question: In test code, a single function is called what?
Question: How many program paths will a function with a single if-else statement have?
Question: What is a program path?
Question: Conceptually, what is a test case?
Question: Besides generally being more organized, why do software developers want to split up their tests into multiple test cases?
Question: Suppose you have a program file that defines the functions foo() and bar(). How many test cases should you have at a minimum in your test code? What should they be named?
4 - Control Flow Graphs
A simple but powerful analysis technique for understanding execution paths through source code.
One approach to systematically exercise the behavior of the system is through basis path testing: identify all program paths in the code and make sure we have at least one test case that exercises every path.
How do we identify all program paths? That is exactly what the control flow graph helps us to do. These graphs can help us to understand what our code does, and also gives us a powerful analysis tool for designing test cases as well as many other applications in computer science.
Definition and uses
A control-flow graph (CFG) is a representation of all program paths that might be traversed through a program during its execution. A program path is a sequence of execution steps like we learned about in debugging.
Frances (Fran) Allen was an IBM Fellow who devised the concept of control flow graphs in the 1960s. In 2006, she became the first woman to receive the Turing Award for her contributions to computer science.
Control flow graphs represent different blocks of code. A basic block is a sequence of non-compound statements and expressions in a program’s code that are guaranteed to execute together, one after the other.
Here are some examples and non-examples of basic blocks:
# A single statement is a basic block.x=1# A sequence of multiple statements and function calls is a basic block.x=5y=x+2z=f(x,y)print(x+y+z)# A basic block can end with a return or raise statement.x=5y=x+2returnf(x,y)# But a sequence of statements with a return/raise in the middle is# NOT a basic block, since the statements after the return/raise aren't# going to execute.x=5returnxy=x+2# Will never execute!# An if statement is not a basic block, since it is a compound statement.# The statements it contains aren't guaranteed to execute one after the other.ifx>5:y=3else:y=4
Typically we treat basic blocks as being maximal, i.e., as large as possible. So if we have a sequence of assignment statements (x = 5, y = x + 2, etc.), we treat them as one big block rather than consisting of multiple single-statement blocks.
Now let’s look at that if statement example in more detail. We can divide it up into three basic blocks: one for the condition (x > 5), then one for the if branch (y = 3) and one for the else branch (y = 4). We can now formalize this idea, and extend it to other kinds of control flow statements like loop.
Formally, a control flow graph (CFG) of a program is a graph \(G = (V,E)\) where:
\(V\) is the set of all (maximal) basic blocks in the program code, plus one special element represent the \(end\) of a program.
\(E\) is the set of edges, where:
There is an edge from block \(b_1\) to block \(b_2\) if and only if the code in \(b_2\) can be executed immediately after the code in \(b_1\).
There is an edge from block \(b\) to the special \(end\) block if and only if the the program can stop immediately after executing the code in block \(b\). This occurs if there is no code written after \(b\), or if \(b\) ends in a return or raise statement.
Building a CFG
Here are the rules:
When you draw a node, you will write either the actual statements or the line numbers inside the rectangle.
Decision nodes: Draw as a diamond or a highlighted rectangle. These are blocks that either (a) transfer control by performing a function_call(), or (b) make a decision with if-else, try-exceptfor, or while. You do not create a decision nodes for built-in functions like print() or input(). A try-except block is a decision node on the try; the except blocks are regular nodes (usually).
Regular nodes: Draw as a rectangle. These are blocks code that executes in sequence without jumping. You group multiple lines of code together into one regular node when they execute in sequence.
End node: Draw two concentric circles with the inner one filled-in. This represents the “end” of the control flow that you are modeling. It does not represent a line of code.
Edges: Draw a line with an arrow at the end to represent the control flow passing from one node to another.
Regular nodes will have a single incoming edge and a single outgoing edge indicating program control flows in and out of the code block.
Decision nodes will have a single incoming edge. They will have either two outgoing edges in the case of if-else, for, and while statements or one outgoing edge if a function_call() that activates a new function. Label the outgoing edge(s) of the decision node with the function_call() or the condition, e.g., x < 0 or x >= 0.
For try nodes, you have a single incoming edge. You have one outgoing edge to the internal nodes of the try, and one outgoing edge to each except and finally block.
The end node can have many incoming edges, and will have no outgoing edges.
We can model a CFG for an entire program, a selected block, or individual functions. CFGs can get lengthy quickly, so you are best off working with separate, small functions.
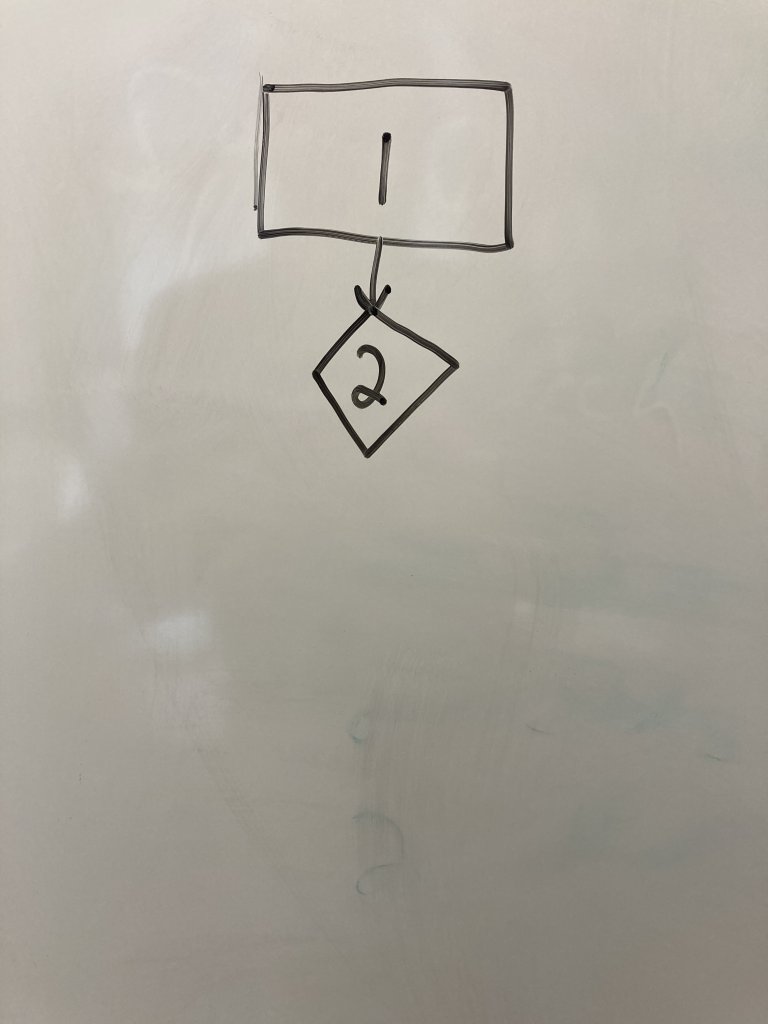
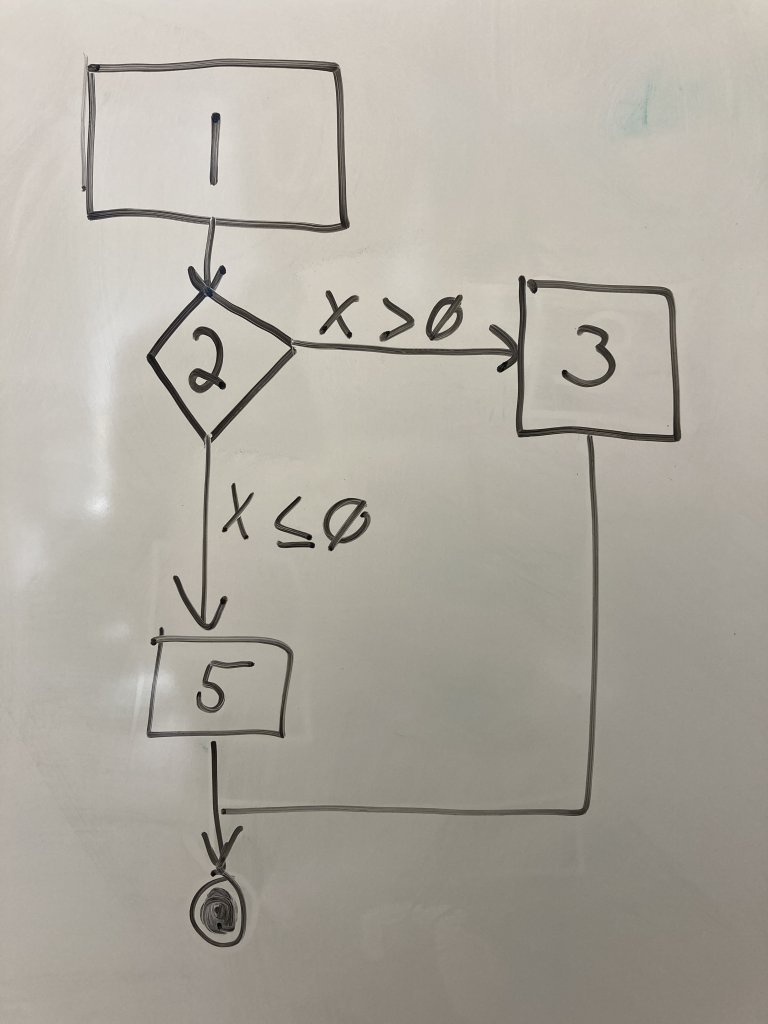
We will use line 1 def check_number(x): as our start point. It is a regular node because no decision is made. Draw a rectangle at the top of a sheet of paper. Write ether the line number or the entire line of code inside the node.
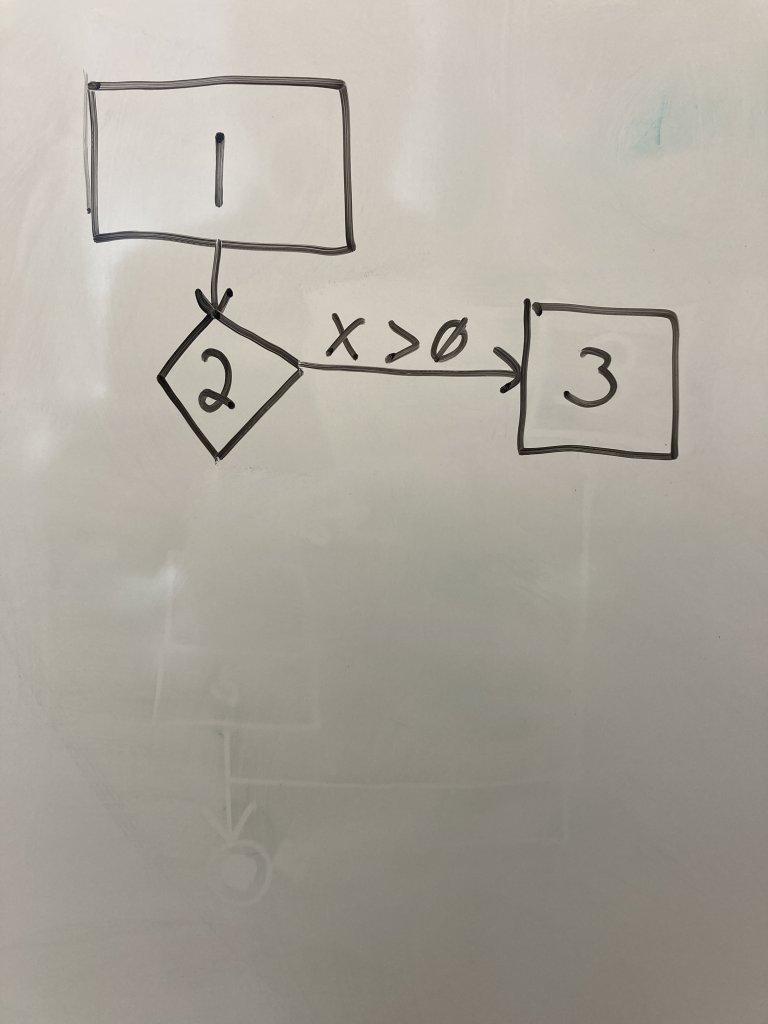
Below the first node, draw a diamond or highlighted rectangle box to represent a decision node for line 2. Decision nodes are used when you encounter if-else, for, or while loops or a call to a user-defined function(). Draw an edge connecting the first node to the second.
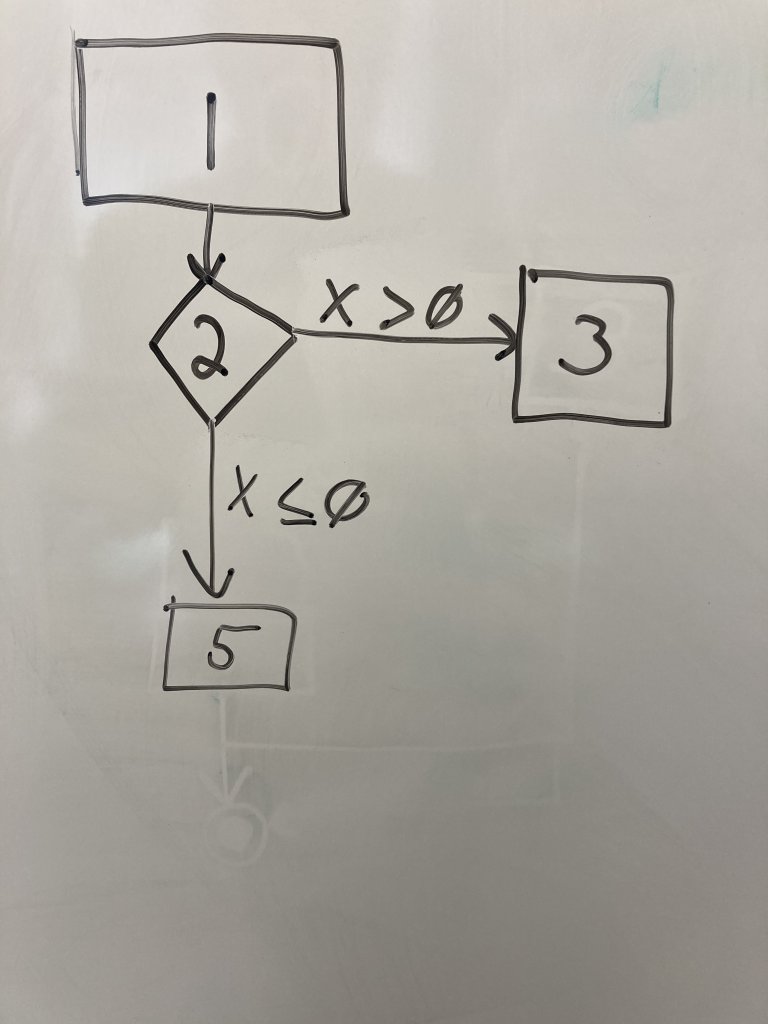
Draw a regular node for line 3 as a rectangle next to the line 2 node. Regular nodes represent blocks of code (in this case only one line) that executes in sequence with no decisions or calls to other functions. Draw an edge from line 2 to line 3 and label it with the condition that transfers control to line 3.
Draw another regular node representing line 5 below the line 2 node. Draw an edge from line 2 to 5 and label it with the condition that transfers control to line 5.Note that we DO NOT draw a node for the else on line 4. It is a part of the if decision node on line 2. However, if we have if-elif, we would draw another decision node. We are just capturing the if comparisons in our graph.
Finally, we need an end node to indicate the end of the program paths. Draw two concentric circles below the other nodes. Connect lines 3 and 5 to this end node. This node does not represent a line of code, but indicates the end of the execution we care about.
Now we have a CFG for a very simple block of code. Tracing the execution of the program becomes a matter of tracing your pen through the nodes and, when you reach decision nodes, determining how the variables values determine the flow of control.
Identifying unique program paths
One of the most important uses of a CFG is that it enables us to identify all the unique program paths in the code. Again, a program path is a sequence of execution steps like we learned about in debugging.
Question: Can how many unique program paths are indicated by the CFG? What are they?
To answer this question, you trace the set of nodes executed during a single “run” of the code block. A path is the set of nodes executed. Note that we have a decision node (line 2). So when the program executes, we have to choose a path, either going through 3 or 5 because the program makes a choice based on the value of x.
So the answer, then, is there are two unique program paths:
The path (1,2,3)
The path (1,2,5)
Now, in basis path testing we will write test code (assertions) with values that exercise all paths at a minimum. So for the above simple example:
Why do we care about the unique program paths? Because we can measure how good our unit tests are based on the number of unique program paths covered. So, our goal becomes to design our test cases so that the set of tests hits every unique program path. Sometimes this is easier said than done. Test coverage is a measure of how many program paths are covered by a test of test cases, and test coverage is used throughout the industry as a measure of test quality. We will use a tool to calculate the test coverage in a future lab.
Exercise: Multiple return paths
The following example has multiple ways to return out of the code block. You would treat raising an exception as returning.
Try to draw the CFG for this example. Some pointers:
Lines 2 and 4 are both decision nodes.
return statements are treated as regular nodes, but they all go to the end node.
Make sure to label your decision nodes’ outgoing edges with the condition.
Exercise: Loop example
Consider the following code that includes a loop.
1
2
3
4
5
6
7
8
9
10
11
defprocess_numbers(nums):evens=0odds=0fornuminnums:ifnum%2==0:print(f"{num} is even")evens+=1else:print(f"{num} is odd")odds+=1returnevens,odds
Try to draw the CFG for this example. Some pointers:
A loop is a decision node. In the case of this for loop, if there are still num remaining in the list, you go to 3. Otherwise, the program block is ended because there is nothing left after the for loop.
Where do you go after lines 4 and 6? Back to the for loop.
Knowledge Check
Question: What is a program path, and how is a CFG related to program paths?
Question: What do you label the outgoing edges of a decision node with?
Question: How many unique program paths exist in the Loop example? What are they?
Question: Write one or more test cases that exercise all unique paths in the Loop example.
Question: Write a test case that exercises all the unique program paths the Multiple return paths example? What are they?
Question: We didn’t model an exception scenario. Apply your critical thinking and the rules at the top of this lab to create a CFG for the following function:
1
2
3
4
5
6
7
8
9
10
11
12
defanalyze_data(data):evens=0odds=0foritemindata:ifisinstance(item,int):ifitem%2==0:evens+=1else:odds+=1else:raiseValueError("Invalid data type")returnevens,odds

{kind=link}

{kind=link}